DiaDem: Advancing Dialogue Descriptions in Audiovisual Video Captioning for Multimodal Large Language Models
DiaDem: Advancing Dialogue Descriptions in Audiovisual Video Captioning for Multimodal Large Language Models
Abstract
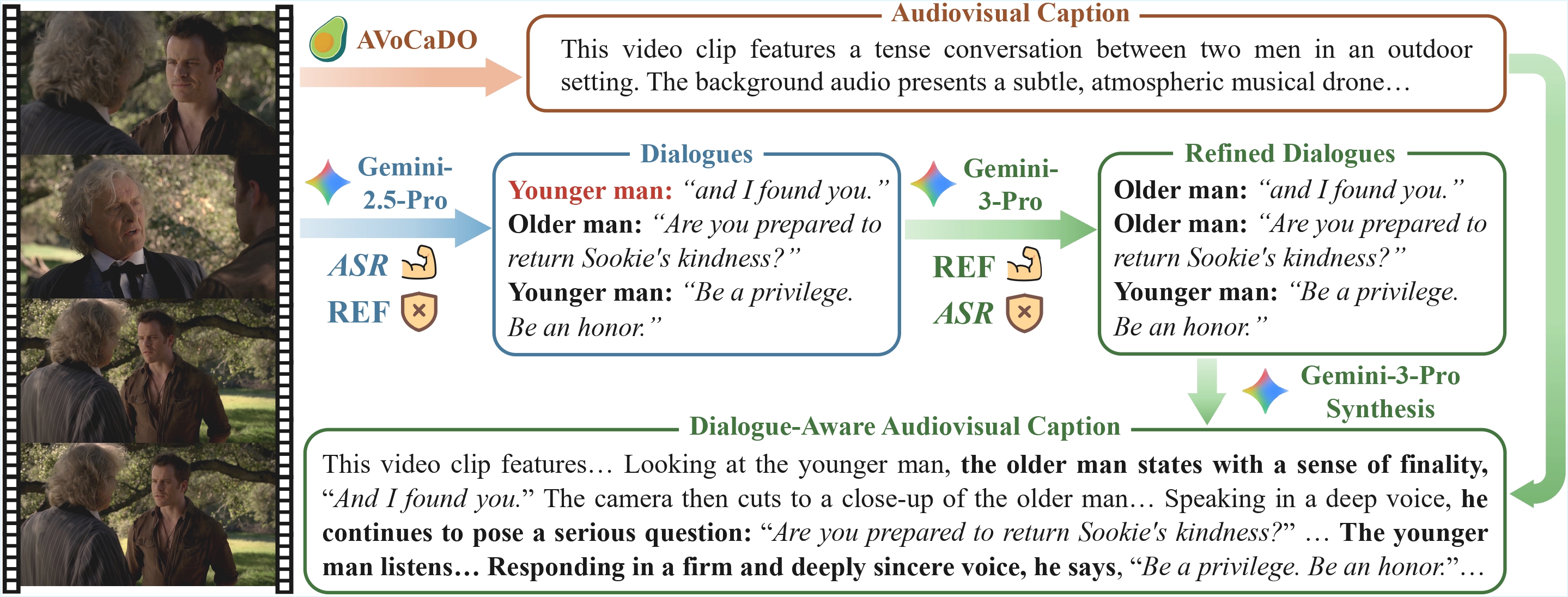
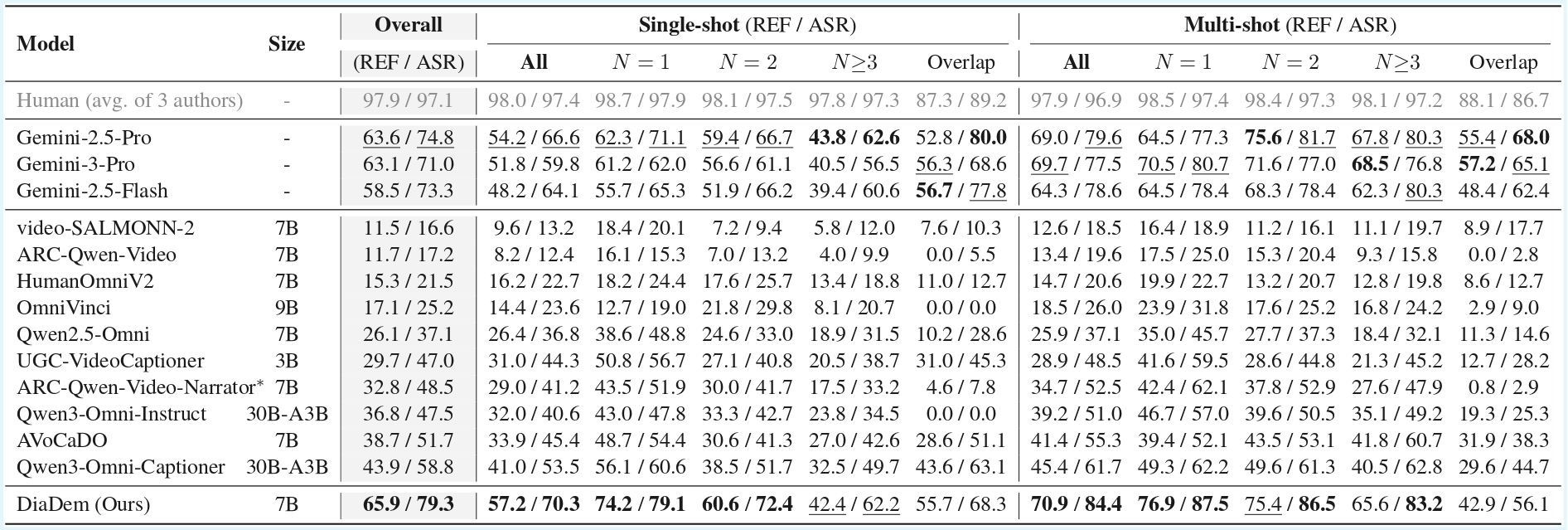
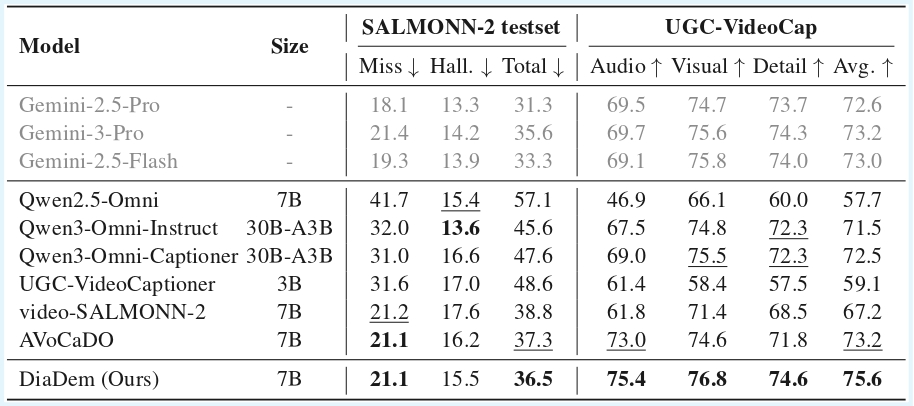
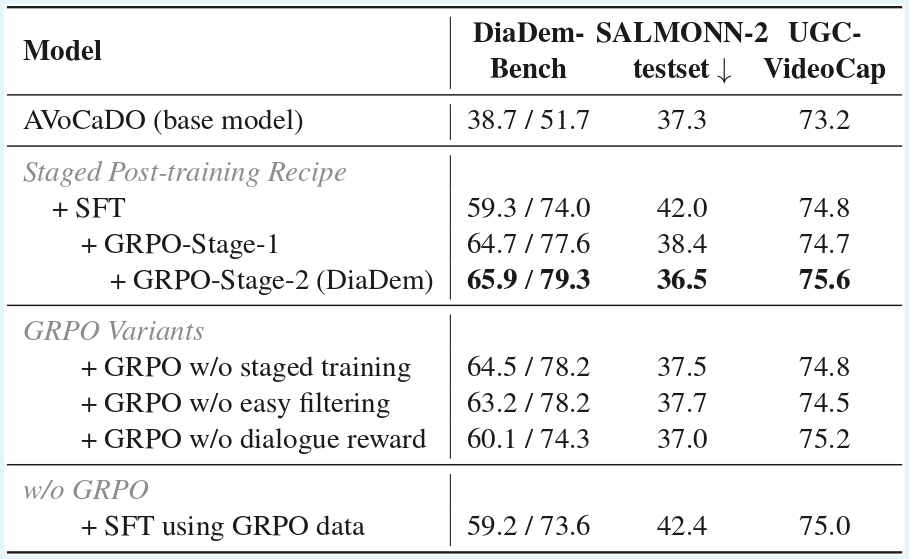
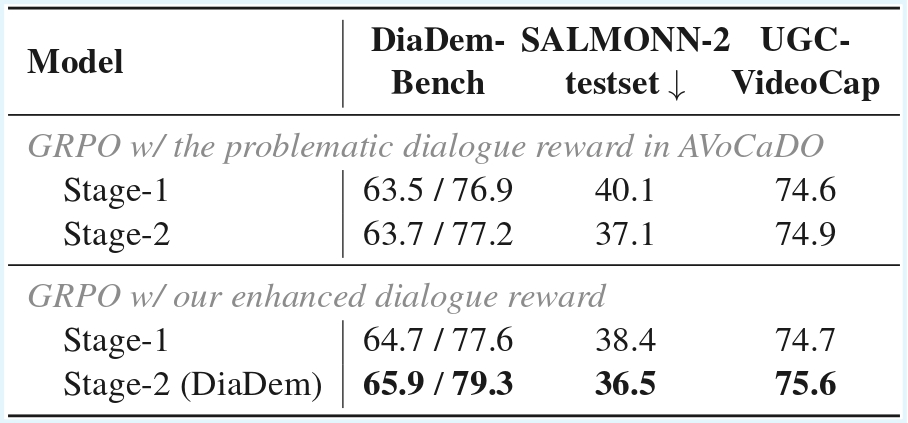
Accurate dialogue description is a critical yet underexplored aspect of audiovisual video captioning, with profound implications for downstream multimodal understanding and generation tasks. Despite the rapid progress in MLLMs, existing approaches often struggle to faithfully capture who says what in complex audiovisual scenes. To mitigate this limitation, we propose DiaDem, a powerful audiovisual video captioning model capable of generating captions with more precise dialogue descriptions, while maintaining strong overall captioning performance across general audiovisual content.
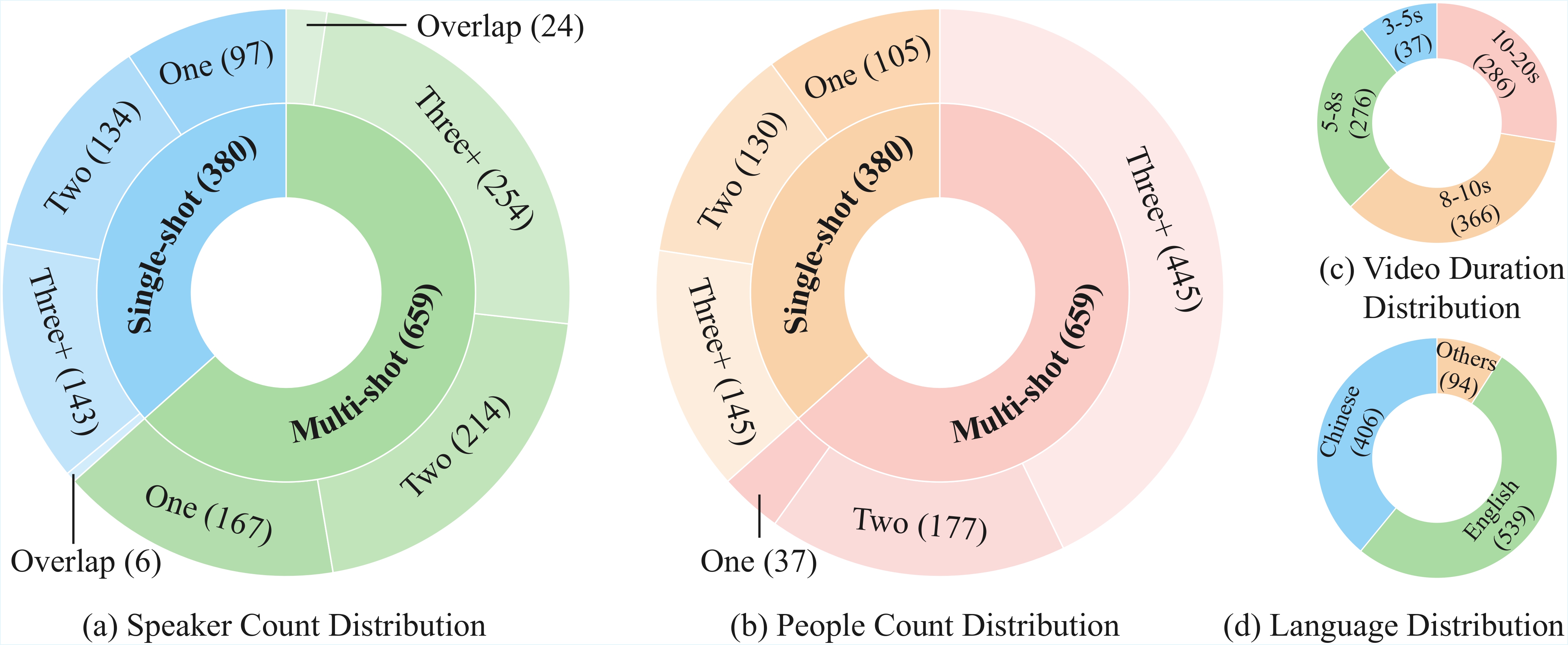
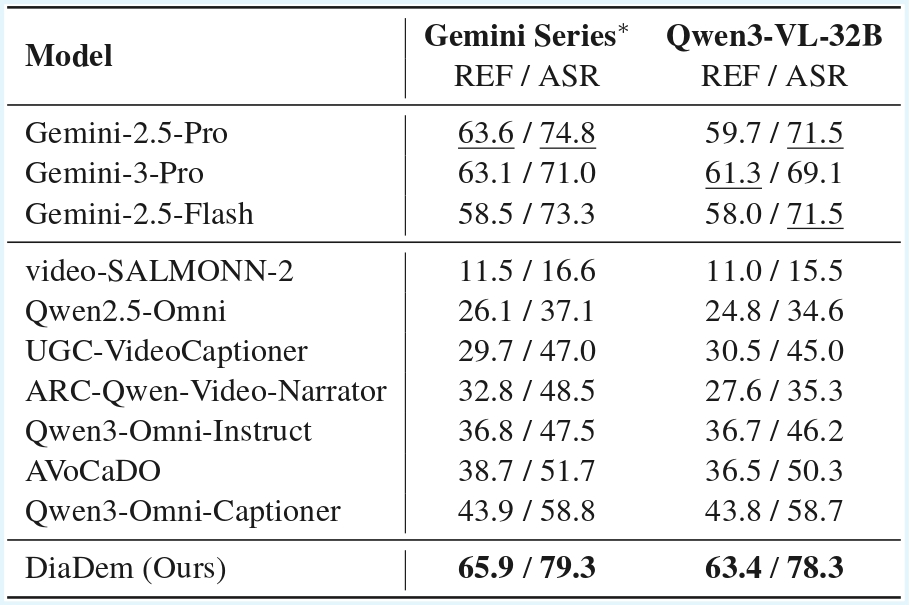
To enable systematic evaluation of dialogue description capabilities, we further introduce DiaDemBench, a comprehensive benchmark designed to evaluate models across diverse dialogue scenarios, emphasizing both speaker attribution accuracy and utterance transcription fidelity in audiovisual captions. Extensive experiments on DiaDemBench reveal that even commercial models still exhibit substantial room for improvement in dialogue-aware captioning. Notably, DiaDem not only outperforms the Gemini series in dialogue description accuracy but also achieves competitive performance on general audiovisual captioning benchmarks, demonstrating its overall effectiveness.